웹 크롤링 Crawl 1편
Crawling 크롤링
파이썬으로 간단하게 Web 페이지 크롤링하기.
인터넷 상의 자료들을 프로그래밍을 하여 Web URL로 받아 분석하여 필요한 정보를 가공하는 작업.
1단계 HTML 그대로 받기
HTML이 있는 URL 주소를 입력하면 대부분 그대로 보이는 페이지를 긁어올 수 있다. (로그인 인증이 필요하거나 특정 조건이 필요한 경우는 고급 방식을 사용해야 한다.)
### daum 기사 수집
import urllib.request
from bs4 import BeautifulSoup
url = 'https://m.media.daum.net/m/media/economic'
conn = urllib.request.urlopen(url)
# art_eco = conn.read()
soup = BeautifulSoup(conn, "html.parser")
# print(soup)
with open('output.txt', 'wt', encoding='utf8') as f:
f.write(str(soup))
print로 출력할 수도 있지만 보통 내용이 많아 파일로 저장해서 분석한다.
스트링 검색으로 원하는 부분을 잘 찾는다.
2단계 HTML 파싱하여 필요한 부분만 뽑기
HTML 내용에서 일부만을 발췌하고 싶다면 HTML 구조를 파악하여 어떻게 필요한 부분만을 select 할 수 있는 방법을 알아야 한다. BeautifulSoup 모듈을 사용하면 그나마 쉽게(?) 추출할 수 있다.
보통 홈페이지의 HTML은 시일이 지나면 업데이트되어 구조가 변경될 경우 기존 select 규칙이 안먹힌다. 그 때 그 때 업데이트를 해주어야 정상적으로 동작할 것이다. (아래 예제가 안돌아가면 스스로 업데이트하길 바란다.)
파싱할 텍스트
<strong class="tit_thumb">
<em class="emph_g"><a class="link_txt #series_title @2" href="/m/media/series/1366383">글로벌포스트</a></em>
<a class="link_txt #article @2" href="http://v.media.daum.net/v/20191023082142459?f=m">中 암호화폐 투자자 "한국 시장은 고사 상태"</a>
</strong>
</li>
<li>
<a class="link_thumb #series_thumb @3" href="http://v.media.daum.net/v/20191023070002158?f=m">
<img alt='[김현석의 월스트리트나우] "트럼프는 워런을 이기고 재선된다"' class="thumb_g" src="//img1.daumcdn.net/thumb/S176x136ht.u/?fname=https%3A%2F%2Fimg1.daumcdn.net%2Fnews%2F201910%2F23%2Fked%2F20191023070003367kwmc.jpg&scode=media"/>
</a>
<strong class="tit_thumb">
<em class="emph_g"><a class="link_txt #series_title @3" href="/m/media/series/465092">월스트리트나우</a></em>
<a class="link_txt #article @3" href="http://v.media.daum.net/v/20191023070002158?f=m">"트럼프는 워런을 이기고 재선된다"</a>
</strong>
태그로 가져오기
위에서 a태그들을 모두 가져와서 출력해 보자.
find_all은 리스트 타입으로 리턴한다. 앞에서부터 발견된 해당 태그들을 리스트 아이템으로 append 추가한다.
보통 너무 많이 출력되서 찾기가 힘들 정도이다. 하나씩 보자.
arta = soup.find_all("a")
print(arta)
출력 결과
[<a class="link_daum #logo" href="http://m.daum.net/" id="daumLogo">
<img alt="Daum" height="25" src="//t1.daumcdn.net/media/news/news2016/m640/tit_daum.png" width="24"/>
</a>, <a class="tit_service #service_news" href="/m/media/" id="kakaoServiceLogo">뉴스</a>, <a class="link_relate link_entertain #service_enter" href="/m/entertain/">연예</a>, <a class="link_relate link_sport #service_sports" href="https://m.sports.media.daum.net/m/sports/">스포츠
</a>, <a class="link_search #GNB#default#search" href="http://mtop.search.daum.net/" id="link_search">
<span class="ico_media ico_search">통합검색</span>
</a>, <a class="link_gnb #media_home" href="/m/media/"><span class="txt_gnb">홈</span></a>, <a class="link_gnb #media_society" href="/m/media/society"><span class="txt_gnb">사회</span></a>, <a class="link_gnb #media_politics" href="/m/media/politics"><span class="txt_gnb">정치</span></a>, <a class="link_gnb #media_economic" href="/m/media/economic"><span class="screen_out">선택됨</span><span class="txt_gnb">경제</span></a>, <a class="link_gnb #media_foriegn" href="/m/media/foreign"><span class="txt_gnb">국제</span></a>, <a class="link_gnb #media_culture" href="/m/media/culture"><span class="txt_gnb">문화</span></a>, <a class="link_gnb #media_digital" href="/m/media/digital"><span class="txt_gnb">IT</span></a>, <a class="link_gnb #media_ranking" href="/m/media/ranking"><span class="txt_gnb">랭킹</span></a>, <a class="link_gnb #media_series" href="/m/media/series"><span class="txt_gnb">연재</span></a>, <a class="link_gnb #media_photo" href="/m/media/photo"><span class="txt_gnb">포토</span></a>, <a class="link_gnb #media_tv" href="/m/media/tv"><span class="txt_gnb">TV</span></a>, <a class="link_gnb #media_1boon" href="/m/media/1boon"><span class="txt_gnb">1boon</span></a>, <a class="link_gnb #media_exhibition" href="https://gallery.v.daum.net/p/home"><span class="txt_gnb">사진전</span></a>, <a class="link_thumb #article_thumb" href="http://v.media.daum.net/v/20191022192703507?f=m">
<img alt='WTO 개도국 지위 간담회 농민 반발로 파행..정부 "곧 결론낼 것"' class="thumb_g" src="//img1.daumcdn.net/thumb/S720x340ht.u/?fname=https%3A%2F%2Fimg1.daumcdn.net%2Fnews%2F201910%2F22%2Fyonhap%2F20191022192703823dgcc.jpg&scode=media"/>
</a>, <a class="link_cont #article_main" href="http://v.media.daum.net/v/20191022192703507?f=m">
<strong class="tit_thumb">WTO 개도국 지위 간담회 농민 반발로 파행..정부 "곧 결론낼 것"</strong>
<span class="info_thumb"><span class="txt_cp">연합뉴스</span><span class="ico_news ico_reply">댓글수</span>25</span>
</a>, <a class="link_relate #article_sub @1" href="http://v.media.daum.net/v/20191022201613686?f=m">
클래스와 ID에 주목하라
보통 태그로 가져오게되면 여러군데 있는 정보들이 마구 섞여서 나온다. index 번호를 잘 찾는다 해도 금방 변경될 수 있다.
그나마 좀 나은 방법은 일반적으로 태그들의 속성이나 클래스를 두어 카테고리화하여 작성한 경우가 많으므로 그 정보들로 데이터를 잘 필터링해야 한다.
클래스로 검색하려면 soup.find 또는 find_all에서 class_=“클래스명” 지정해 주고, ID로 검색하려면 파라미터에 id=“아이디” 를 추가한다.
위 a 태그들 중에 기사 제목같은 것만 뽑고 싶은데, 클래스를 잘 보면 link_news 라고 된 부분만 추출해 보자.
arta = soup.find_all("a", class_='link_news')
print(arta)
output
[<a class="link_news #RANKING#popular_female#article @1" href="http://v.media.daum.net/v/20191022040803988?f=m">
<em class="txt_age emph_g2">
<span class="num_news age20">20</span>대<span class="txt_arr">↓</span> </em>
심상찮은 경제 2위 중국·4위 독일.. R의 공포 급속 확산
</a>, <a class="link_news #RANKING#popular_female#article @2" href="http://v.media.daum.net/v/20191023143008200?f=m">
<em class="txt_age emph_g2">
<span class="num_news age30">30</span>대 </em>
'내일채움공제' 첫 5년 만기자 탄생..중기부 "정책 확대·개선하겠다"
</a>, <a class="link_news #RANKING#popular_female#article @3" href="http://v.media.daum.net/v/20191023161257078?f=m">
<em class="txt_age emph_g2">
어느 정도 뽑히면 이제 내부를 탐색
a 태그중 link_news 클래스 속성이 있는 것을 다 뽑았다. 여기서 딱 제목만 뽑고 싶은데…
태그내에 있는 텍스트만 추출하면?
a태그 하나씩 가져와서 텍스트만 출력하는데 텍스트 앞뒤 공백을 제거하자.
arta = soup.find_all("a", class_='link_news')
for art in arta:
print(art.text.strip())
output
20대↓
심상찮은 경제 2위 중국·4위 독일.. R의 공포 급속 확산
30대
'내일채움공제' 첫 5년 만기자 탄생..중기부 "정책 확대·개선하겠다"
40대
액상형 전자담배 '사용자제→중단' 권고..청소년 즉시중단
거의 다 나온 것 같은데, 쓸데없는 스트링이 더 있었다. 잘 보면 em 태그에 있는 것이 연령대 스트링이 추가된 것이다. 뒤에 기사제목이 별도의 태그가 없어서 태그로 추출도 어렵다.
이때는 내용들을 분해해서 list로 받아 index를 찾으면 된다. 하위 개체들 중 마지막이 해당 텍스트가 될 것이다.
arta = soup.find_all("a", class_='link_news')
for art in arta:
print( art.contents[-1].strip() )
output
'내일채움공제' 첫 5년 만기자 탄생..중기부 "정책 확대·개선하겠다"
환자 1명이 '졸피뎀' 1만1456정 구입..국내 처방환자 176만명
액상형 전자담배 '사용자제→중단' 권고..청소년 즉시중단
돌아온 미세먼지의 나날들..'잿빛 하늘' 내년 봄까지 이어질 듯
구조조정 나선 LG디스플레이, 올해 적자 1조원 넘어설 듯
정부 "'개도국 포기' 논의" 농민들 불렀지만..시작부터 '아수라장'
경영난 위워크, 결국 손정의 품으로.."100억달러 더 투입"
이탄희 "검찰 전관예우 더 심각, 전화 한통 값 수천만원"
깔끔하게 제목만 뽑을 수 있었다.
좀 더 편하게 찾을 수는 없을까?
브라우저의 개발자 모드(F12 키를 누르면 나온다.)에서 원하는 텍스트를 찾아서 검사 또는 element 보기를 하면 해당 텍스트의 상위 태그 및 속성 정보들을 모두 볼 수 있다. 오른쪽창에서 해당 텍스트 위치가 있는 소스로 이동한다. 하단보면 태그 구조가 나온다.
이를 기반으로 필터링 규칙을 잘 잡으면 빨리 찾을 수 있을 것이다.
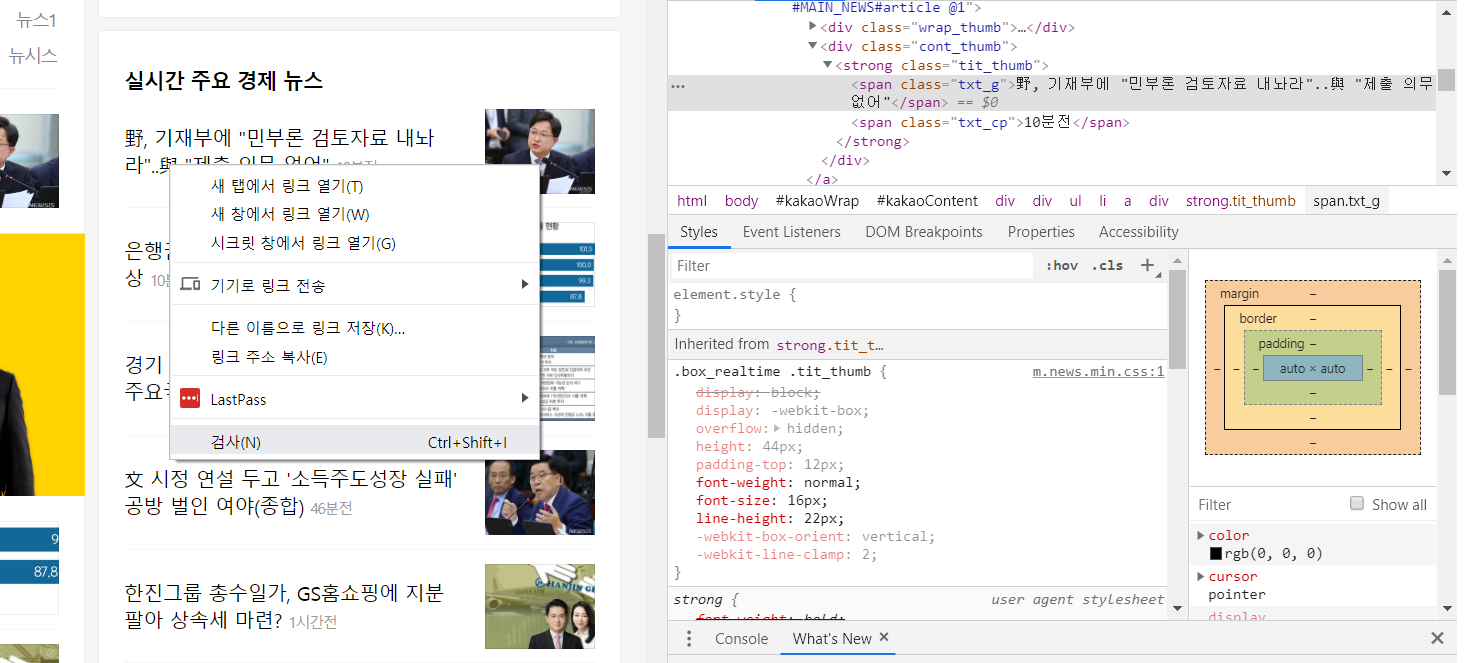
위의 부분을 한 번 찾아보려고 시도했는데…
subnews = soup.find("div", "section_sub")
realnews = subnews.find("div", "box_realtime")
print(realnews)
news = soup.find("span", "txt_g")
print(news)
결과는
<div class="box_g box_realtime">
<h3 class="tit_g">실시간 주요 경제 뉴스</h3>
<ul category="economic" class="list_thumb">
</ul>
<a class="link_more #MAIN_NEWS#more" href="#none">더보기<span class="ico_news"></span></a>
</div>
None
안타깝게도 정보가 없다. 우리가 원하는 정보는 list_thumb 클래스ul 태그 내부인데 비어 있다.
실제로 이러한 경우가 종종 있다. 이 경우는 보통 html을 요청했을 때, javascript가 포함되어 브라우저에서 작동시켜야 내용이 채워지는 경우들이다. 따라서 html 자체만을 보는 것으로는 원하는 결과를 얻을 수 없다.
귀찮지만 이럴때는 다른 방식을 사용해야 한다.
가상의 브라우저를 만들어 JS를 구동시킨 결과를 파싱하면 되는 것이다.
다음화에서 계속…
Author: crazyj7@gmail.com